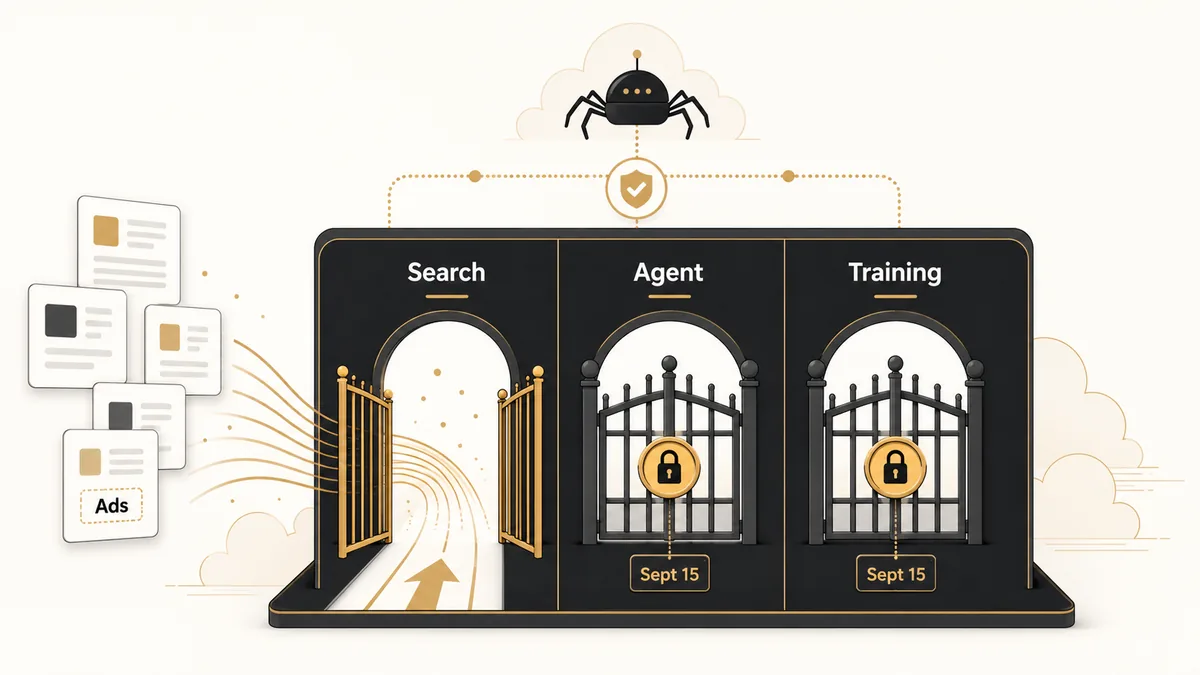
Cloudflare said on July 1 that, starting September 15, 2026, it will set new default rules for AI crawler traffic: Search stays allowed by default, while Training and Agent traffic will be blocked by default on pages that display ads.
The change matters because Cloudflare is no longer treating AI crawlers as one bucket. Its new controls split bot purpose into Search, Agent, and Training, while its managed robots.txt support can now add a use=reference content-use signal for sites that already allow search but block AI training.
For B2B marketers, this is not only a publisher rights story. It is a crawl-policy deadline. When we covered ChatGPT-User crawling B2B sites 3.6x more than Googlebot, the practical problem was already visible: teams need separate decisions for retrieval, training, and search access. Cloudflare just put a date on that work.
Key takeaways:
- Cloudflare’s new defaults take effect on September 15, 2026.
- Search crawlers remain allowed by default; Training and Agent crawlers are blocked by default on ad-supported pages.
- Cloudflare is giving site owners separate controls for Search, Agent, and Training traffic.
- Managed robots.txt can now express
search=yes, ai-train=no, use=referencefor content-use preferences. - B2B teams should audit resource hubs, blogs, ad-supported pages, and gated content before the default changes take effect.
What Cloudflare Actually Changed
Cloudflare’s announcement separates crawler intent from crawler identity. A bot used for search indexing is no longer treated the same as a bot used for real-time AI agents or model training. That matters because some large crawlers historically mixed those purposes under one name, which left site owners with an awkward choice: allow the crawler for search visibility, or block it to protect content from AI use.
Under the new default, Cloudflare says Training and Agent categories will be blocked on pages that display ads, unless the site owner changes the setting. Search remains allowed. Cloudflare AI Crawl Control is available across plans and gives owners visibility into which AI services access their content.
The managed robots.txt layer adds a second signal. Cloudflare’s Content Signals documentation says the policy can express separate preferences for search, AI input, and AI training. The new use=reference value tells crawlers the owner permits indexing, excerpts, and links back, not full reproduction.
Why B2B Content Teams Should Care
The obvious impact is on publishers with ad-supported pages. The quieter impact is on any B2B company that treats its blog, comparison pages, glossaries, research library, or help center as part of the demand engine.
If your site runs ads, sponsorship units, or partner placements on content pages, the default could block mixed-use crawlers from those pages. If your site does not run ads, the new control model still changes the governance conversation. The search team, content team, legal team, and marketing ops team now need a shared answer to one question: which bot purpose is allowed on which content type?
Our read: the winning answer is not “block AI.” It is a content map. Public product pages, comparison pages, and educational posts usually want search and AI retrieval access. Proprietary research, customer portals, gated PDFs, and data exports need tighter rules. The CNN and Perplexity copyright fight shows why content supply is being repriced; Cloudflare is turning that market pressure into infrastructure defaults.
The Ranking Catch: Search Access Is Still Different
Cloudflare’s split is useful because it keeps Search separate from Training and Agent use. That is the ranking catch. A B2B brand that blocks every bot labeled AI may protect content, but it may also reduce the chance that AI answer engines retrieve its pages when buyers ask comparison or vendor-shortlist questions.
The practical SEO move is to avoid broad category panic. Start with pages that actually drive discovery: category explainers, buying guides, alternative pages, data-led posts, and customer-proof pages. Those are the pages most likely to appear in answer engines and AI citation systems where brand mentions and source links already diverge.
Then separate them from content that should not train a model or answer a public query: internal documentation, customer-only materials, raw templates, paid reports, and partner-only assets. The crawler decision should follow the business value of each content type, not a sitewide default copied from someone else’s thread.
What Teams Should Do Before September 15
Run a two-column crawler audit. List your top content directories on one side and the allowed bot purpose on the other: Search, Agent, Training, or none. The important part is the distinction. “AI crawlers” is no longer specific enough.
Check AI Crawl Control before the date. Cloudflare’s crawler management docs show per-crawler actions inside the dashboard. Confirm the default for the domains and page types that carry ads or sponsorship blocks.
Put robots.txt under marketing governance. Robots rules used to sit with SEO or engineering. In 2026 they affect AI visibility, licensing posture, and content monetization. The owner should be named in the same way GEO ownership now needs one accountable operator.
Watch Pay Per Use, not only Pay Per Crawl. Cloudflare’s 2025 Pay Per Crawl beta introduced allow, charge, and block options. The new announcement points toward payment when content shapes AI answers. That is still early, but it is where the market is moving.
For B2B teams, the fastest win is simple: know which content should be found, which content should be licensed, and which content should stay out of both training and answer surfaces. The September 15 date makes the audit easier to schedule and harder to defer.
Frequently Asked Questions
Cloudflare says its new defaults will block Training and Agent crawler categories on pages that display ads, while keeping Search allowed by default. Site owners can still adjust settings, but mixed-use crawlers will face a clearer access test.
No. B2B sites should separate crawler purpose by content type. Public buying guides and comparison pages usually benefit from AI retrieval. Proprietary docs, customer portals, paid reports, and raw data exports need stricter rules.
The direct effect depends on the crawler and page type. Search crawlers remain a separate category, which is the point of the change. The risk comes from broad blocking that removes useful content from AI retrieval or answer surfaces where buyers now research vendors.
SEO or marketing ops should own the audit with input from legal, content, and engineering. The decision affects discoverability, licensing posture, analytics, and site infrastructure, so leaving it as a purely technical setting is too narrow.