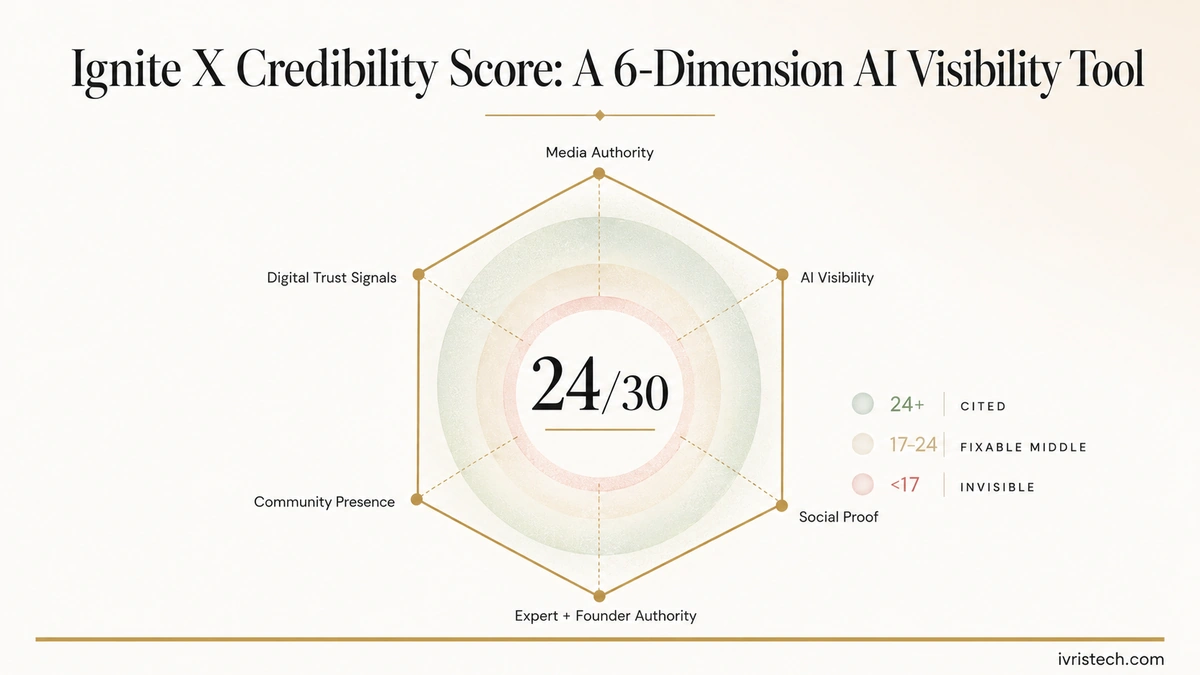
Ignite X, the San Francisco PR and AI-advisory agency, launched the Credibility Score on May 14, a first-of-a-kind diagnostic that rates B2B brands across six dimensions of how AI search engines perceive them. The scale runs 1 to 5 in each dimension for a 30-point total. Brands above 24 are consistently cited by ChatGPT, Claude, Perplexity, and Gemini. Brands below 17 are functionally invisible to AI search, regardless of how well-known they are inside their category.
Carmen Hughes, Ignite X’s founder, has been advising AI-native startups since 2016, which gives the methodology more weight than a typical new diagnostic in the AI-visibility category. The six dimensions (media authority, AI visibility, social proof, expert and founder authority, community presence, and digital trust signals) were derived from the surfaces AI engines actually cite, not from the legacy brand framework most marketing diagnostics inherit from the 1990s.
For B2B marketing teams trying to make AI visibility a measurable discipline, the Credibility Score sits in a different category from the tracking tools that have dominated the AEO conversation. Tools like Profound and Ahrefs Brand Radar tell you whether you appear in AI answers. The Credibility Score tells you why you appear or don’t, and what to fix first. Our read: this is the first scoring framework that translates the “how AI sees your brand” question into a roadmap a CMO can actually delegate.
Key Takeaways
- Launch date: May 14, 2026. From Ignite X, a San Francisco PR and AI-advisory agency founded by Carmen Hughes (Top 20 SF Agency five years running).
- The six dimensions: media authority, AI visibility, social proof, expert and founder authority, community presence, and digital trust signals. Each scored 1 to 5 for a 30-point total.
- The two thresholds: Brands above 24/30 are consistently cited by ChatGPT, Claude, Perplexity, and Gemini. Brands below 17/30 are functionally invisible to AI search. The 17-24 band is the “fixable middle” most B2B brands sit in.
- Benchmark feature: Every Credibility Score includes a side-by-side comparison against three direct competitors plus a prioritized fix roadmap ranked by likely score impact.
- The diagnostic premise: AI engines cite 2 to 7 sources per response, and the top citation position captures nearly all the referral value. The score is built around that asymmetry: being one of the top 2 cited sources matters far more than being one of 50 indexed pages.
What the Six Dimensions Actually Measure
Each dimension is mapped to a specific surface AI engines pull from when assembling an answer. The framing is operational rather than abstract.
Media authority measures coverage in journalism and trade publications AI engines weight as primary sources. Wikipedia entries, named expert quotes in business press, and editorial citations in publications like the Wall Street Journal or Wired all contribute. AI visibility measures direct citation frequency across the four major engines, the metric most existing AEO tools already report. Social proof measures third-party review-platform depth across G2, Trustpilot, TrustRadius, and Capterra, the same surfaces that drove the Trustpilot citation surge inside ChatGPT earlier this year. Expert and founder authority measures the digital footprint of named individuals at the company: LinkedIn presence, conference speaking, podcast appearances, original research credited by name.
Community presence measures discussion in Reddit, Stack Overflow, Discord servers, and vertical subs where buyers congregate. 5W’s May 2026 citation index already showed Reddit hits roughly 40% citation frequency across every major AI engine; the Credibility Score formalizes Reddit (and Reddit-equivalent communities) as a measurable visibility dimension. Digital trust signals are the boring-but-decisive layer: HTTPS, schema markup, dateModified accuracy, named authorship on key pages, and the absence of red flags AI engines penalize (paid review patterns, sudden link spikes, content farms).
The 1-to-5 scoring inside each dimension is anchored to specific evidence thresholds rather than a generic rubric. A brand with three Wikipedia entries scores differently from a brand with one, and the differential is the same across categories. That comparability is what makes the 30-point total a useful number rather than a vanity metric.
The 24-vs-17 Threshold Is the Operational Center
The data point most B2B marketers should anchor on is the 24-of-30 citation threshold. Brands above 24 appear consistently in AI answers across all four major engines. Brands below 17 are functionally invisible. Inside the 17-24 band sits the “fixable middle”: brands that show up sporadically depending on prompt phrasing, engine, or query context.
The asymmetry between cited and invisible is what makes the score actionable. Moving from 21 to 24 is a different exercise from moving from 28 to 30. The 21-to-24 climb crosses the citation threshold and unlocks a step-change in AI exposure; the 28-to-30 climb is incremental improvement to an already-cited brand. The Credibility Score’s prioritized roadmap is structured around that asymmetry. Recommendations for sub-24 brands focus on the cheapest path to crossing 24, not on optimizing what’s already strong.
A worked example from the Ignite X data: a B2B tech company evaluated at 19/30 appeared in only 50% of purchase-intent buyer queries, while a competitor at 27/30 appeared in 86%. The 36-percentage-point gap in visibility came from an 8-point score gap. The mapping isn’t perfectly linear, but the threshold dynamic is consistent across the categories Ignite X has scored to date.
How It Stacks Against Existing AI Visibility Tools
The Credibility Score isn’t a replacement for citation-tracking tools. It answers a different question. The honest comparison:
Profound, Ahrefs Brand Radar, and the new wave of vendor-side dashboards tell you whether and how often your brand appears in AI answers. They are measurement layers, the rear-view mirror. The Credibility Score tells you why your appearances are what they are, which dimension is dragging you down, and what to fix first. It’s the diagnostic layer, the dashboard light that says which subsystem needs attention.
For B2B teams already running a measurement tool, the Credibility Score is complementary, not duplicative. The measurement tool tells you the symptom (we’re cited 12% of the time); the Credibility Score tells you the cause (digital trust signals score 2/5 because three core pages are missing schema markup). For B2B teams not running anything yet, the diagnostic is arguably the better starting point. It answers the question “what should we even be doing differently” before the measurement question “how often are we showing up.”
The dimension that benefits most directly from the diagnostic framing is expert and founder authority. Citation tools can tell you the founder shows up in 4% of category queries. The Credibility Score tells you the founder scores 1/5 because there is no consolidated LinkedIn presence, no named original research, and no podcast footprint. That’s a 90-day work plan, not a measurement readout. Gartner’s 2026 CMO Spend data showed mature AI-ready CMOs are concentrating budget on foundation layers like this, which is exactly the kind of work the Credibility Score’s prioritized roadmap surfaces.
What B2B Brands Should Do With This
Five moves are worth the next 60 days if AI visibility is on the B2B marketing roadmap:
1. Run the diagnostic before adding any new AI-visibility tool. The Credibility Score answers what to fix; measurement tools answer how it’s trending. Running diagnostic before measurement is the right order. Pay for the diagnostic, then decide whether the measurement spend is worth it based on which dimensions you need to improve.
2. Score founders and executives independently. The “expert and founder authority” dimension is the one most B2B brands score lowest on. It’s also the dimension with the highest ROI per dollar spent. A founder with a strong LinkedIn presence, two named original research drops per quarter, and three to five podcast appearances per year can carry a brand from sub-17 to above-24 on that single dimension alone.
3. Audit the digital trust signals dimension first. It’s the cheapest fix and the most leveraged. Schema markup, named authorship, dateModified accuracy, HTTPS hygiene, none requires a content strategy or a budget reallocation. A 90-day technical sprint can move this dimension from 2/5 to 4/5 for most B2B brands, which by itself often crosses the 17-to-24 threshold for visibility.
4. Compare against three competitors at the dimension level, not the score level. Ignite X’s benchmark feature surfaces competitor scores across all six dimensions. The actionable read is not “they’re 27 and we’re 21.” It’s “they score 5/5 on community presence because of a Reddit footprint we don’t have.” Dimension-level competitive analysis tells you which buckets to invest in to close the gap fastest.
5. Re-score quarterly, not monthly. The score moves slowly enough that monthly tracking is noise. Quarterly cycles align with the lag time of the underlying signals. Wikipedia changes, review-platform depth, LinkedIn following, and community presence all change on a 90-day timescale. B2B buyer research patterns are sticky enough that the data doesn’t refresh week to week.
The Honest Limitation
The diagnostic surface the Credibility Score doesn’t measure is execution. A brand can score 28/30 on the diagnostic and still lose to a competitor in the AI answer surface if the competitor’s content is structurally more extractable: clearer H2 hierarchies, tighter FAQ markup, named statistics in opening paragraphs. The Credibility Score evaluates the input layers (presence across the six surfaces); it doesn’t evaluate the output layer (whether your specific pages are structured for AI lift).
That’s not a critique of the framework so much as a clarification of scope. Ignite X already pairs the diagnostic with Machine Relations, its execution practice for improving the signals the score surfaces. The clean model: Credibility Score diagnoses where a brand is weak; Machine Relations is the remedy that works across earned media, structured first-party content, founder authority, community presence, and citation monitoring. For teams handling the work internally, a structural content audit still belongs beside that plan (the AI Overview optimization playbook covers the page-level side).
The other limitation worth naming: the score is calibrated against current AI engine behavior. ChatGPT, Claude, Perplexity, and Gemini all change their citation logic on a quarterly cadence, and a six-dimension framework calibrated in May 2026 will need recalibration by November. Ignite X has acknowledged the framework is treated as living, with the threshold bands and dimension weights subject to revision as engine behavior evolves.
Frequently Asked Questions
Media authority, AI visibility, social proof, expert and founder authority, community presence, and digital trust signals. Each is scored 1 to 5 against specific evidence thresholds for a 30-point total. The dimensions are mapped to the surfaces AI engines actually cite when assembling answers: Wikipedia and trade press for media authority, Reddit and vertical communities for community presence, schema-rich pages for digital trust signals.
Per Ignite X’s data, brands scoring above 24/30 appear consistently in AI answers across ChatGPT, Claude, Perplexity, and Gemini. Brands below 17/30 are functionally invisible regardless of category recognition. The 17-to-24 band is the “fixable middle” where most B2B brands sit, and the prioritized roadmap that ships with each score is structured to identify the cheapest path to crossing 24.
Profound and Ahrefs Brand Radar measure citation frequency. They tell you whether and how often your brand appears in AI answers. The Credibility Score is a diagnostic, not a measurement tool: it tells you why your appearances are what they are, which dimension is dragging your visibility down, and what to fix first. The two layers are complementary; running both is a stronger setup than running either alone.
Ignite X is a San Francisco-based PR and AI-advisory agency founded by Carmen Hughes, who has been working with AI startups since 2016. The firm has been named a Top 20 San Francisco agency for five consecutive years. The Credibility Score was derived from the surfaces AI engines actually cite in production, not from a legacy brand framework, which gives it a tighter fit to the citation behavior B2B brands are trying to influence.